I recently read “Adventure Time: Volume 1″, a comic book based on the smart animated series of the same name. In the comic, I found some odd looking messages at the bottom of two pages, which turned out to be encrypted text. Here’s how, with a fair few hours of my life and the help of some Ruby scripts, I cracked The Adventure Time Cipher.
Finding the Cryptic Messages
I first spotted something interesting at the bottom of one of the pages, a collection of symbols:

Slightly puzzled, I continued reading. However, when a similar looking message turned up again later in the comic, I couldn’t ignore it:

I’ve seen these symbols before, this is a Pigpen cipher (more on that in a minute).
Back when I was studying Computer Security, we spent a lot of time learning about various different types of encryption; from simple monoalphabetic substitution ciphers (such as Pigpen, ROT13, Caesar), to more complex polyalphabetic substitution ciphers (like the Vigenère and Engima). We also studied cryptanalysis, the art of breaking encryption techniques.
Cryptanalysis is a lot of fun. Let’s see if it’s possible to decode those messages.
The Pigpen Cipher
A cipher is an algorithm for encrypting something. A ciphertext is the message in its encrypted form.
In the case of this comic book, there are two ciphertexts (encrypted messages):
![]()

Here are my initial thoughts:
- this looks like a Pigpen cipher (those symbols are very distinctive)
- there are 22 unique symbols, and 2 punctuation marks (an apostrophe and hyphen)
- both ciphertexts end in the same 9 symbols, this repeated pattern suggests they are a) encrypted using the same key, b) there is potentially some significance in the last 9 symbols.
![]()
The Pigpen cipher works by mapping letters to symbols, typically using an A-Z configuration across 4 grids. The example below shows how the word “HELLO” would be encrypted with a standard Pigpen configuration:

This should be easy, let’s map each symbol to its corresponding character and we’ll have our decrypted message in no time!
![]()
VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG
Ciphertext 1 decrpyted using the standard Pigpen configuration
EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG
Ciphertext 2 decrpyted using the standard Pigpen configuration
Hmm, that didn’t work. Guess this is going to be a little more complicated. Let’s try something else.
Pigpen Brute-force Key Rotation
It’s not uncommon for simple substitution ciphers to use an offset/rotation. As there are 26 characters in the English alphabet, there are 26 possible rotations of the Pigpen cipher, as demonstrated below:
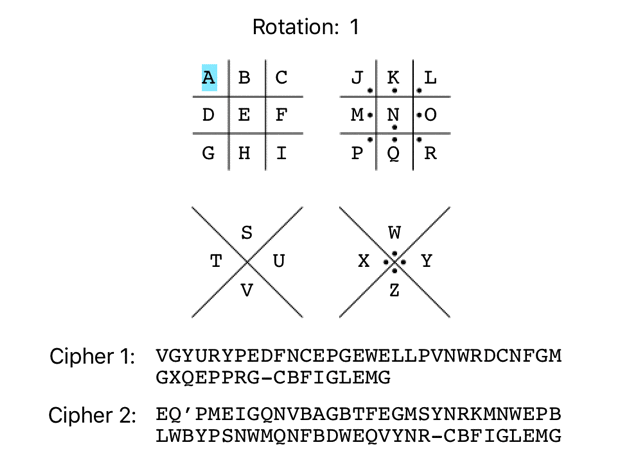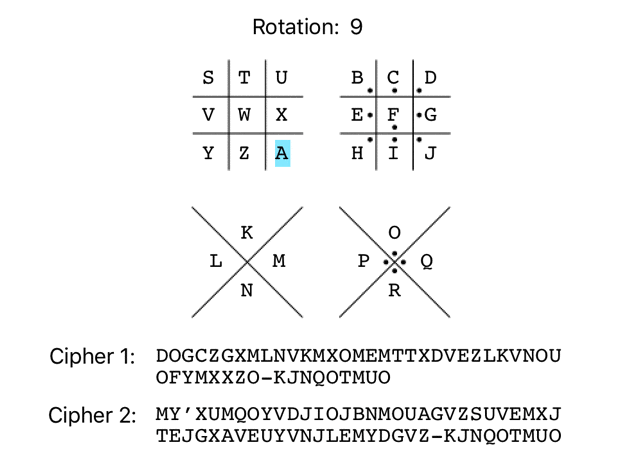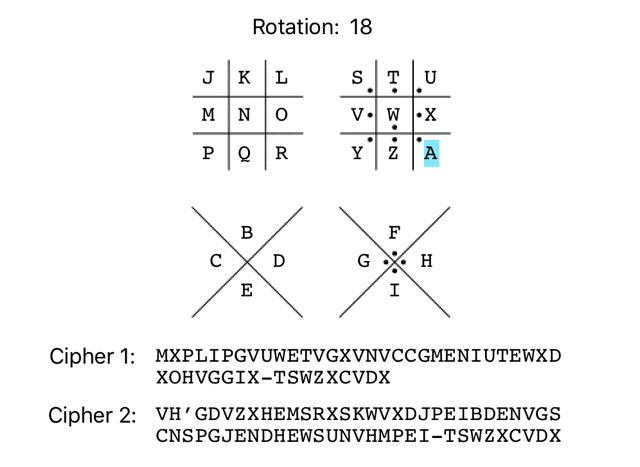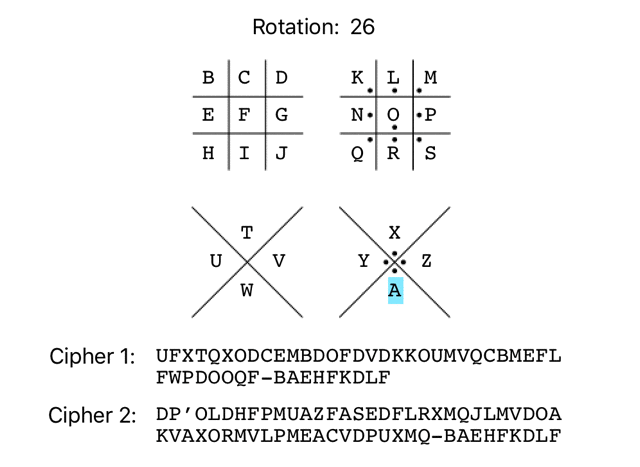
It’s possible to check all 26 possible rotations very easily with a few lines of Ruby. To keep it simple, I’ll be using the alphabetic representation of the initial Pigpen rotation in the ‘ciphertexts’ array going forward, instead of dealing with the complexity of supporting Pigpen symbols in my script.
| ciphertexts = [ |
| “VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG“, |
| “EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG“ |
| ] |
| key = (‘A‘..‘Z‘).to_a |
| ciphertexts.each do |ciphertext| |
| (0..25).each do |rotation| |
| puts ciphertext.tr(key.join, key.rotate(rotation).join) |
| end |
| end |
Here are the 26 possible rotations for ciphertext 1:
VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG WHZVSZQFEGODFQHFXFMMQWOXSEDOGHNHYRFQQSH-DCGJHMFNH XIAWTARGFHPEGRIGYGNNRXPYTFEPHIOIZSGRRTI-EDHKINGOI YJBXUBSHGIQFHSJHZHOOSYQZUGFQIJPJATHSSUJ-FEILJOHPJ ZKCYVCTIHJRGITKIAIPPTZRAVHGRJKQKBUITTVK-GFJMKPIQK ALDZWDUJIKSHJULJBJQQUASBWIHSKLRLCVJUUWL-HGKNLQJRL BMEAXEVKJLTIKVMKCKRRVBTCXJITLMSMDWKVVXM-IHLOMRKSM CNFBYFWLKMUJLWNLDLSSWCUDYKJUMNTNEXLWWYN-JIMPNSLTN DOGCZGXMLNVKMXOMEMTTXDVEZLKVNOUOFYMXXZO-KJNQOTMUO EPHDAHYNMOWLNYPNFNUUYEWFAMLWOPVPGZNYYAP-LKORPUNVP FQIEBIZONPXMOZQOGOVVZFXGBNMXPQWQHAOZZBQ-MLPSQVOWQ GRJFCJAPOQYNPARPHPWWAGYHCONYQRXRIBPAACR-NMQTRWPXR HSKGDKBQPRZOQBSQIQXXBHZIDPOZRSYSJCQBBDS-ONRUSXQYS ITLHELCRQSAPRCTRJRYYCIAJEQPASTZTKDRCCET-POSVTYRZT JUMIFMDSRTBQSDUSKSZZDJBKFRQBTUAULESDDFU-QPTWUZSAU KVNJGNETSUCRTEVTLTAAEKCLGSRCUVBVMFTEEGV-RQUXVATBV LWOKHOFUTVDSUFWUMUBBFLDMHTSDVWCWNGUFFHW-SRVYWBUCW MXPLIPGVUWETVGXVNVCCGMENIUTEWXDXOHVGGIX-TSWZXCVDX NYQMJQHWVXFUWHYWOWDDHNFOJVUFXYEYPIWHHJY-UTXAYDWEY OZRNKRIXWYGVXIZXPXEEIOGPKWVGYZFZQJXIIKZ-VUYBZEXFZ PASOLSJYXZHWYJAYQYFFJPHQLXWHZAGARKYJJLA-WVZCAFYGA QBTPMTKZYAIXZKBZRZGGKQIRMYXIABHBSLZKKMB-XWADBGZHB RCUQNULAZBJYALCASAHHLRJSNZYJBCICTMALLNC-YXBECHAIC SDVROVMBACKZBMDBTBIIMSKTOAZKCDJDUNBMMOD-ZYCFDIBJD TEWSPWNCBDLACNECUCJJNTLUPBALDEKEVOCNNPE-AZDGEJCKE UFXTQXODCEMBDOFDVDKKOUMVQCBMEFLFWPDOOQF-BAEHFKDLF
And ciphertext 2:
EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG FR’QNFJHROWCBHCUGFHNTZOSLNOXFQCMXCZQTOXNROGCEXFRWZOS-DCGJHMFNH GS’ROGKISPXDCIDVHGIOUAPTMOPYGRDNYDARUPYOSPHDFYGSXAPT-EDHKINGOI HT’SPHLJTQYEDJEWIHJPVBQUNPQZHSEOZEBSVQZPTQIEGZHTYBQU-FEILJOHPJ IU’TQIMKURZFEKFXJIKQWCRVOQRAITFPAFCTWRAQURJFHAIUZCRV-GFJMKPIQK JV’URJNLVSAGFLGYKJLRXDSWPRSBJUGQBGDUXSBRVSKGIBJVADSW-HGKNLQJRL KW’VSKOMWTBHGMHZLKMSYETXQSTCKVHRCHEVYTCSWTLHJCKWBETX-IHLOMRKSM LX’WTLPNXUCIHNIAMLNTZFUYRTUDLWISDIFWZUDTXUMIKDLXCFUY-JIMPNSLTN MY’XUMQOYVDJIOJBNMOUAGVZSUVEMXJTEJGXAVEUYVNJLEMYDGVZ-KJNQOTMUO NZ’YVNRPZWEKJPKCONPVBHWATVWFNYKUFKHYBWFVZWOKMFNZEHWA-LKORPUNVP OA’ZWOSQAXFLKQLDPOQWCIXBUWXGOZLVGLIZCXGWAXPLNGOAFIXB-MLPSQVOWQ PB’AXPTRBYGMLRMEQPRXDJYCVXYHPAMWHMJADYHXBYQMOHPBGJYC-NMQTRWPXR QC’BYQUSCZHNMSNFRQSYEKZDWYZIQBNXINKBEZIYCZRNPIQCHKZD-ONRUSXQYS RD’CZRVTDAIONTOGSRTZFLAEXZAJRCOYJOLCFAJZDASOQJRDILAE-POSVTYRZT SE’DASWUEBJPOUPHTSUAGMBFYABKSDPZKPMDGBKAEBTPRKSEJMBF-QPTWUZSAU TF’EBTXVFCKQPVQIUTVBHNCGZBCLTEQALQNEHCLBFCUQSLTFKNCG-RQUXVATBV UG’FCUYWGDLRQWRJVUWCIODHACDMUFRBMROFIDMCGDVRTMUGLODH-SRVYWBUCW VH’GDVZXHEMSRXSKWVXDJPEIBDENVGSCNSPGJENDHEWSUNVHMPEI-TSWZXCVDX WI’HEWAYIFNTSYTLXWYEKQFJCEFOWHTDOTQHKFOEIFXTVOWINQFJ-UTXAYDWEY XJ’IFXBZJGOUTZUMYXZFLRGKDFGPXIUEPURILGPFJGYUWPXJORGK-VUYBZEXFZ YK’JGYCAKHPVUAVNZYAGMSHLEGHQYJVFQVSJMHQGKHZVXQYKPSHL-WVZCAFYGA ZL’KHZDBLIQWVBWOAZBHNTIMFHIRZKWGRWTKNIRHLIAWYRZLQTIM-XWADBGZHB AM’LIAECMJRXWCXPBACIOUJNGIJSALXHSXULOJSIMJBXZSAMRUJN-YXBECHAIC BN’MJBFDNKSYXDYQCBDJPVKOHJKTBMYITYVMPKTJNKCYATBNSVKO-ZYCFDIBJD CO’NKCGEOLTZYEZRDCEKQWLPIKLUCNZJUZWNQLUKOLDZBUCOTWLP-AZDGEJCKE DP’OLDHFPMUAZFASEDFLRXMQJLMVDOAKVAXORMVLPMEACVDPUXMQ-BAEHFKDLF
Poot on a newt, no luck, again. I was hoping that one of the rotations would reveal a plaintext message, but I guess this isn’t a standard Pigpen key after all.
Frequency Analysis
Time to get smarter. Pigpen ciphers are an example of a monoalphabetic substitution cipher (also known as a simple substitution cipher), where one cipher value maps to one alphabetic value. In the previous example where we encrypted “HELLO”, every “E” is encrypted to, and only to, a “□” – there is a one-to-one mapping between those two characters.

These types of ciphers are susceptible to frequency analysis. Frequency analysis is the study of the distribution of letters in a ciphertext, how often letters (or in this case, symbols) appear in an encrypted message. Frequency analysis is dependent on the fact that not all letters in the English language are equal, ‘E’ is much more likely to appear in a given sentence than the letter ‘Z’ for example. The image below shows the typical distribution of letters in English language text (source):
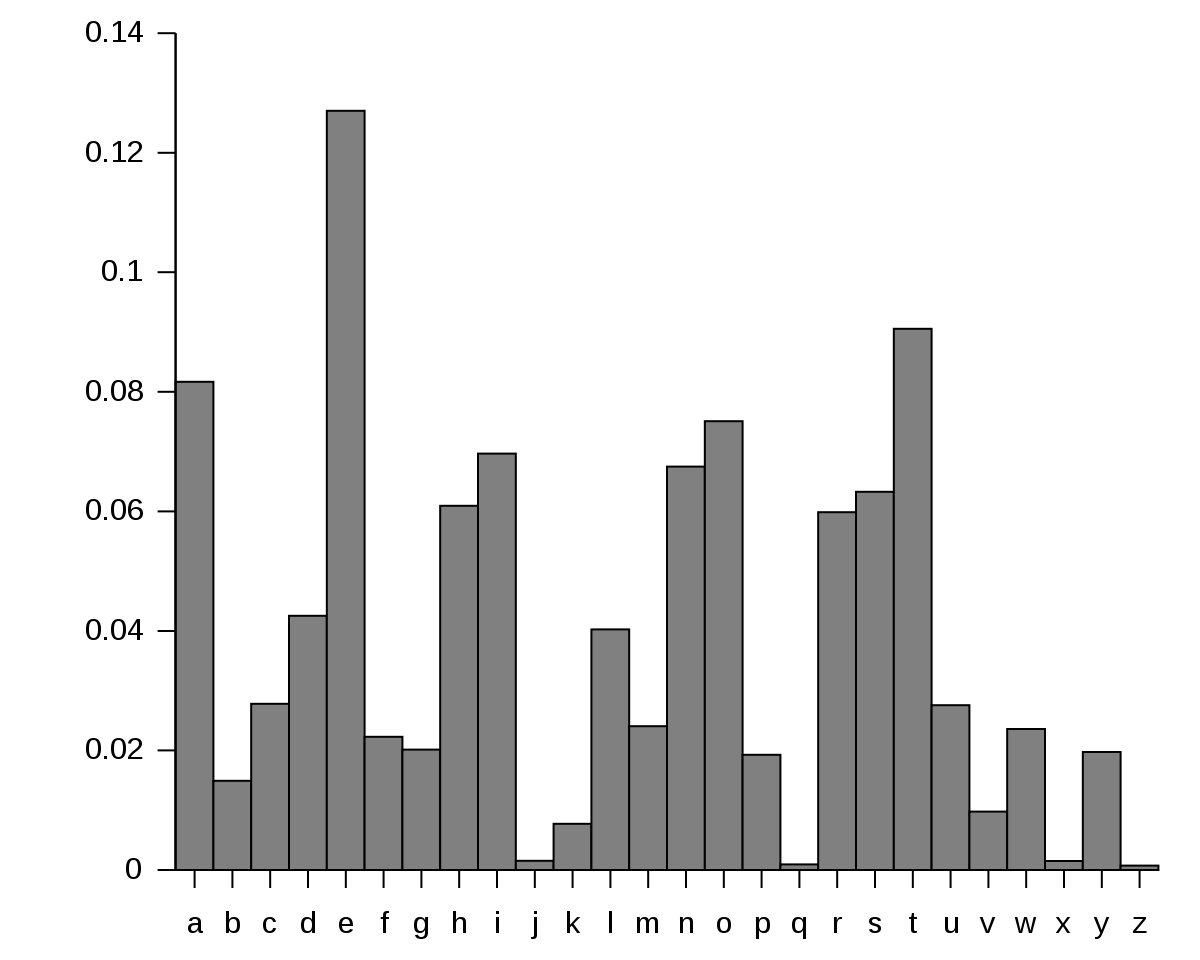
We can use this known “typical distribution” to infer mappings between encrypted letters and their plaintext equivalent. Frequency analysis works best with a large corpus of ciphertext (short ciphertexts are less likely to have significant distributions), which is bad news for me as I have two very short ciphertexts. However, because both ciphertexts appear to be encrypted with the same key (both have the same repeated 9-character pattern at the end), we can combine them and analyse as a single ciphertext to help reduce the impact of distorted frequencies. The following script takes all of the ciphertext characters, sorts them by their frequency (high to low), and then maps them to the known typical English distribution. The expectation being that the ciphertext character that appears most often in the encrypted messages would map to the letter ‘E’, the second most common character would map to ‘T’, and so on:
ciphertexts = [ “VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG“, “EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG“ ] english_freqs = “ETAOINSHRDLCUMWFGYPBVKJXQZ“.chars # count letter frequencies in ciphertexts char_freqs = Hash.new(0) (ciphertexts.join).each_char {|c| char_freqs[c] += 1} # sort by letter frequency freqs (descending) ciphertext_freqs = Hash[char_freqs.sort_by{|k,v| –v}] # remove non-alphanumeric ciphertext chars (e.g. punctuation) (ciphertext_freqs.keys – english_freqs).each {|p| ciphertext_freqs.delete(p)} # display the letter and frequency mappings puts “Ciphertext => English (count)“ ciphertext_freqs.each_with_index do |ct_freq,index| puts “#{ct_freq.first} => #{english_freqs[index]} (#{ct_freq.last})“ end used_english_freqs = english_freqs[0..ciphertext_freqs.count–1].join cipher_char_freqs = ciphertext_freqs.keys.join ciphertexts.each do |ciphertext| ciphertext_before = ciphertext ciphertext_after = ciphertext.tr(cipher_char_freqs, used_english_freqs) puts “Ciphertext before: #{ciphertext_before}“ puts “Ciphertext after: #{ciphertext_after}“
| end |
Output:
Ciphertext => English (count) E => E (12) G => T (12) N => A (9) P => O (8) M => I (7) B => N (7) F => S (6) W => H (6) Q => R (5) R => D (5) Y => L (5) L => C (5) V => U (4) C => M (4) D => W (3) I => F (3) S => G (2) A => Y (1) X => P (1) T => B (1) U => V (1) K => K (1) Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: UTLVDLOEWSAMEOTEHECCOUAHDWMASTITPREOODT-MNSFTCEIT Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: ER’OIEFTRAUNYTNBSETIGLADKIAHEONCHNLOGAHIRASNWHERULAD-MNSFTCEIT
No clear success from that, although this is complicated by the fact a lot of the ciphertext characters have the same frequency (e.g. ‘E’ and ‘G’ with a count of 12, ‘M’ and ‘B’ with a count of 7), which means that there are a lot of possible permutations to try. I think these are symptomatic of having very short ciphertexts to work with. Moving on…
Brute force
I’ve tried to brute force the rotation (with 26 different possible combinations), and frequency analysis, with no luck. How about brute forcing every single possible key combination (that is, every possible permutation of the 26 characters of the alphabet mapped to the Pigpen symbols)?
We can calculate how many possible permutations of the cipher key there are. We know we have 26 characters in the English alphabet, and each ciphertext symbol can only map to a single English character:
- for the ciphertext symbol ‘□’, we can map 1 of 26 possible English characters (A – Z). Let’s say ‘A’.
- for the next ciphertext symbol, we can map 1 of 25 possible English characters (B – Z).
- and so on, for the 24 remaining English characters
The number of possible keys can be represented as 26 X 25 X […] X 2 X 1 possible combinations, or written another way, 26! (26 factorial). If we calculate 26!, we get:
26! ≈ 400,000,000,000,000,000,000,000,000 potential key combinations.
To put this into perspective, if we could try a single permutation once every microsecond, it would take:
400,000,000,000,000,000,000,000,000/1000000/60/60/24/365 = 12,683,916,793,506 years
Or put another way, significantly longer than the current age of the universe!
Signature analysis
I’ve exhausted some of the more straightforward cryptanalysis techniques, so it’s back to the drawing board. It’s probably time to revisit that repeated character sequence that features at the end of both ciphertexts.
![]()
The repeated pattern with a preceding hyphen looks like a sign-off/signature of some sort, could this be a message from someone? Perhaps the comic book author, illustrator, or an Adventure Time character?
Let’s take a look at some potential options (with a little help from Wikipedia):
- Ryan North (comic creator)
- Shelli Paroline (comic illustrator)
- Braden Lamb (comic illustrator)
- Finn the Human
- Jake the Dog
- Princess Bubblegum
- BMO
- Marceline the Vampire Queen
- Lumpy Space Princess
- Lady Rainicorn
- Flame Princess
Of these, those that could fit as a 9 character sign-off are:
- Ryan North
- Bubblegum
- Marceline
- Rainicorn
Let’s try a quick script that matches the 9 character signature with each potential name:
ciphertexts = [ “VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG“, “EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG“ ] names = [ “RYANNORTH“, “BUBBLEGUM“, “MARCELINE“, “RAINICORN“ ] signature = “CBFIGLEMG“ known_keys = signature.chars all_keys = (“A“..“Z“).to_a unknown_keys = (all_keys – known_keys) names.each do |name| puts “Name: #{name}“ ciphertexts.each do |ciphertext| ciphertext_before = ciphertext ciphertext_after = ciphertext.tr(signature, name) ciphertext_known_keys = ciphertext.tr(unknown_keys.join, “_“).tr(signature, name) puts “Ciphertext before: #{ciphertext_before}“ puts “Ciphertext after: #{ciphertext_after}“ puts “Ciphertext known keys: #{ciphertext_known_keys}“ end
| end |
Output:
Name: RYANNORTH Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VHYURYPRDANRRPHRWROOPVNWRDRNAHTHXQRPPRH-RYANHORTH Ciphertext known keys: _H_____R_A_RR_HR_ROO______R_AHTH__R___H-RYANHORTH Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: RQ’PTRNHQNVYAHYTARHTSYNRKTNWRPYOWYYPSNWTQNAYDWRQVYNR-RYANHORTH Ciphertext known keys: R_’_TRNH___Y_HY_ARHT_____T__R_YO_Y_____T__AY__R_____-RYANHORTH Name: BUBBLEGUM Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VMYURYPGDBNBGPMGWGEEPVNWRDBNBMUMXQGPPRM-BUBBMEGUM Ciphertext known keys: _M_____G_B_BG_MG_GEE______B_BMUM__G___M-BUBBMEGUM Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: GQ’PUGBMQNVUAMUTBGMUSYNRKUNWGPUEWUYPSNWUQNBUDWGQVYNR-BUBBMEGUM Ciphertext known keys: G_’_UGBM___U_MU_BGMU_____U__G_UE_U_____U__BU__G_____-BUBBMEGUM Name: MARCELINE Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYURYPIDRNMIPEIWILLPVNWRDMNRENEXQIPPRE-MARCELINE Ciphertext known keys: _E_____I_R_MI_EI_ILL______M_RENE__I___E-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IQ’PNICEQNVAAEATRIENSYNRKNNWIPALWAYPSNWNQNRADWIQVYNR-MARCELINE Ciphertext known keys: I_’_NICE___A_EA_RIEN_____N__I_AL_A_____N__RA__I_____-MARCELINE Name: RAINICORN Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VNYURYPODINROPNOWOCCPVNWRDRNINRNXQOPPRN-RAINNCORN Ciphertext known keys: _N_____O_I_RO_NO_OCC______R_INRN__O___N-RAINNCORN Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: OQ’PRONNQNVAANATIONRSYNRKRNWOPACWAYPSNWRQNIADWOQVYNR-RAINNCORN Ciphertext known keys: O_’_RONN___A_NA_IONR_____R__O_AC_A_____R__IA__O_____-RAINNCORN
Interesting! The signature has repeated characters at the 5th and 9th position which means that 3 out of 4 of the attempted signatures failed to be mapped correctly:
- RYANNORTH becomes RYANHORTH
- BUBBLEGUM becomes BUBBMEGUM
- MARCELINE becomes MARCELINE
- RAINICORN becomes RAINNCORN
With the repeated characters at those particular positions, only MARCELINE can fit as a signature (which is very handy!), which gives ciphertext 1 and 2 as:
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYURYPIDRNMIPEIWILLPVNWRDMNRENEXQIPPRE-MARCELINE Ciphertext known keys: _E_____I_R_MI_EI_ILL______M_RENE__I___E-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IQ’PNICEQNVAAEATRIENSYNRKNNWIPALWAYPSNWNQNRADWIQVYNR-MARCELINE Ciphertext known keys: I_’_NICE___A_EA_RIEN_____N__I_AL_A_____N__RA__I_____-MARCELINE
It’s reassuring to see the word “NICE” (highlighted in green) crop up in the second ciphertext. My friend Vivien is looking over my shoulder at this point, as I stare blankly at the output of the script. “That could be it’s at the beginning [of the second ciphertext], right?” he says, i.e.
Ciphertext known keys: I_’_NICE_[...] Ciphertext known keys: IT’SNICE_[...]
Sounds good to me, let’s try it! Time for another script. Let’s map all the guessed characters to the ciphertexts; we have MARCELINE plus two new mappings for the T and S of IT’S (mapping T => Q, S => P):
ciphertexts = [ “VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG“, “EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG“ ] key_mappings = “MARCELINETS“ cipher_keys = “CBFIGLEMGQP“ known_keys = cipher_keys.chars all_keys = (“A“..“Z“).to_a unknown_keys = (all_keys – known_keys) ciphertexts.each do |ciphertext| ciphertext_before = ciphertext ciphertext_after = ciphertext.tr(cipher_keys, key_mappings) ciphertext_known_keys = ciphertext.tr(unknown_keys.join, “_“).tr(cipher_keys, key_mappings) puts “Ciphertext before: #{ciphertext_before}“ puts “Ciphertext after: #{ciphertext_after}“ puts “Ciphertext known keys: #{ciphertext_known_keys}“
| end |
Which gives:
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYURYSIDRNMISEIWILLSVNWRDMNRENEXTISSRE-MARCELINE Ciphertext known keys: _E____SI_R_MISEI_ILLS_____M_RENE_TISS_E-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IT’SNICETNVAAEATRIENSYNRKNNWISALWAYSSNWNTNRADWITVYNR-MARCELINE Ciphertext known keys: IT’SNICET__A_EA_RIEN_____N__ISAL_A_S___NT_RA__IT____-MARCELINE
Now “TISS_E” (highlighted above) in the first cipher looks like “TISSUE”. Let’s map R => U, which gives us:
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYUUYSIDRNMISEIWILLSVNWUDMNRENEXTISSUE-MARCELINE Ciphertext known keys: _E__U_SI_R_MISEI_ILLS___U_M_RENE_TISSUE-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IT’SNICETNVAAEATRIENSYNUKNNWISALWAYSSNWNTNRADWITVYNU-MARCELINE Ciphertext known keys: IT’SNICET__A_EA_RIEN___U_N__ISAL_A_S___NT_RA__IT___U-MARCELINE
At this point, there are 12 attempted mappings. What’s interesting is that other words are beginning to appear outside of the known keys, but in the initial Pigpen rotation (highlighted below):
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYUUYSIDRNMISEIWILLSVNWUDMNRENEXTISSUE-MARCELINE Ciphertext known keys: _E__U_SI_R_MISEI_ILLS___U_M_RENE_TISSUE-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IT’SNICETNVAAEATRIENSYNUKNNWISALWAYSSNWNTNRADWITVYNU-MARCELINE Ciphertext known keys: IT’SNICET__A_EA_RIEN___U_N__ISAL_A_S___NT_RA__IT___U-MARCELINE
This could be a coincidence, but we potentially have:
- I WILL
- NEXT ISSUE (ha, this makes much more sense than my first guess of TISSUE)
- IS ALWAYS
Mapping these guesses gives us: X => X, W => W, Y => Y (i.e. unchanged from the original cipher permutation):
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYUUYSIDRNMISEIWILLSVNWUDMNRENEXTISSUE-MARCELINE Ciphertext known keys: _EY_UYSI_R_MISEIWILLS__WU_M_RENEXTISSUE-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IT’SNICETNVAAEATRIENSYNUKNNWISALWAYSSNWNTNRADWITVYNU-MARCELINE Ciphertext known keys: IT’SNICET__A_EA_RIEN_Y_U_N_WISALWAYS__WNT_RA_WIT_Y_U-MARCELINE
Y_U appears twice above, let’s try YOU (mapping N => O):
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: VEYUUYSIDROMISEIWILLSVOWUDMORENEXTISSUE-MARCELINE Ciphertext known keys: _EY_UYSI_ROMISEIWILLS_OWU_MORENEXTISSUE-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IT’SNICETOVAAEATRIENSYOUKNOWISALWAYSSOWNTORADWITVYOU-MARCELINE Ciphertext known keys: IT’SNICETO_A_EA_RIEN_YOU_NOWISALWAYS_OWNTORA_WIT_YOU-MARCELINE
We’re definitely gaining momentum, nice! Let’s take a look at where both ciphertexts are at, and try and add some whitespace for good measure:
Ciphertext known keys: _EY_UYSI_ROMISE I WILL S_OWU_ MORE NEX TISSUE - MARCELINE Ciphertext known keys: IT’S NICE TO _A_EA_RIEN_ YOU _NOW IS ALWAYS _OWN TO RA_WIT_ YOU - MARCELINE
Some potential new words from above:
- _ROMISE = PROMISE
- WIT_ YOU = WITH YOU
Gives us: D => P, V => H:
Ciphertext before: VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG Ciphertext after: HEYUUYSIPROMISEIWILLSHOWUPMORENEXTISSUE-MARCELINE Ciphertext known keys: HEY_UYSIPROMISEIWILLSHOWUPMORENEXTISSUE-MARCELINE Ciphertext before: EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG Ciphertext after: IT’SNICETOHAAEATRIENSYOUKNOWISALWAYSSOWNTORAPWITHYOU-MARCELINE Ciphertext known keys: IT’SNICETOHA_EA_RIEN_YOU_NOWISALWAYS_OWNTORAPWITHYOU-MARCELINE
Awesome, it looks like there’s enough here to solve both ciphertexts:
HEY_UYSIPROMISEIWILLSHOWUPMORENEXTISSUE-MARCELINEHEY _UYS I PROMISE I WILL SHOW UP MORE NEXT ISSUE - MARCELINE IT’SNICETOHA_EA_RIEN_YOU_NOWISALWAYS_OWNTORAPWITHYOU-MARCELINE IT’S NICE TO HA_E A _RIEN_ YOU _NOW IS ALWAYS _OWN TO RAP WITH YOU - MARCELINE
- HEY _UYS = HEY GUYS
- HA_E = HAVE
- _RIEN_ = FRIEND
- _NOW = KNOW
- _OWN = DOWN
Adding the missing mappings (U => G, A => V, T => F, S => D, K => K) to complete the script:
ciphertexts = [ “VGYURYPEDFNCEPGEWELLPVNWRDCNFGMGXQEPPRG-CBFIGLEMG“, “EQ’PMEIGQNVBAGBTFEGMSYNRKMNWEPBLWBYPSNWMQNFBDWEQVYNR-CBFIGLEMG“ ] cipher_keys = “CBFIGLEMGQPRXWYNVDUATSK“ key_mappings = “MARCELINETSUXWYOHPGVFDK“ known_keys = cipher_keys.chars all_keys = (“A“..“Z“).to_a unknown_keys = (all_keys – known_keys) ciphertexts.each do |ciphertext| ciphertext_before = ciphertext ciphertext_after = ciphertext.tr(cipher_keys, key_mappings) ciphertext_known_keys = ciphertext.tr(unknown_keys.join, “_“).tr(cipher_keys, key_mappings) puts “Ciphertext before: #{ciphertext_before}“ puts “Ciphertext after: #{ciphertext_after}“ puts “Ciphertext known keys: #{ciphertext_known_keys}“
| end |
Here are the solved ciphers next to the original screenshots:
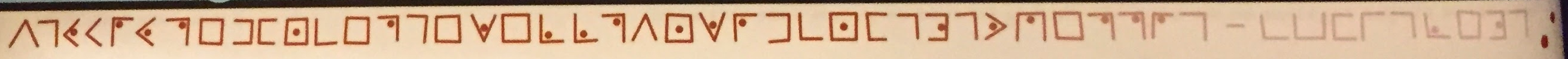
“HEY GUYS I PROMISE I WILL SHOW UP MORE NEXT ISSUE – MARCELINE”. A promise from Marceline to show up more in the second comic.
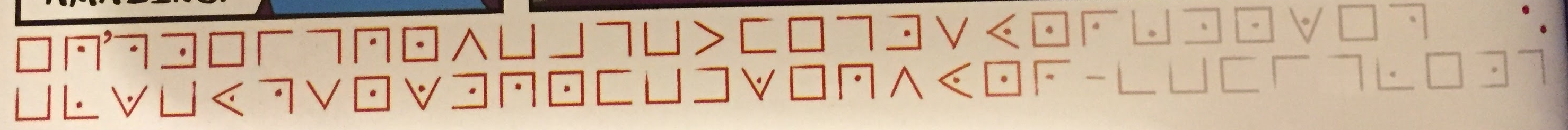
“IT’S NICE TO HAVE A FRIEND YOU KNOW IS ALWAYS DOWN TO RAP WITH YOU – MARCELINE”. Marceline and Finn used some improvised rap battle skills together in this story.
Mapping all the known characters back to the Pigpen code reveals something amazing; VAMPIRE. Of course! Marceline is a vampire, which also explains the little red dots – of blood – next to each ciphertext signature:
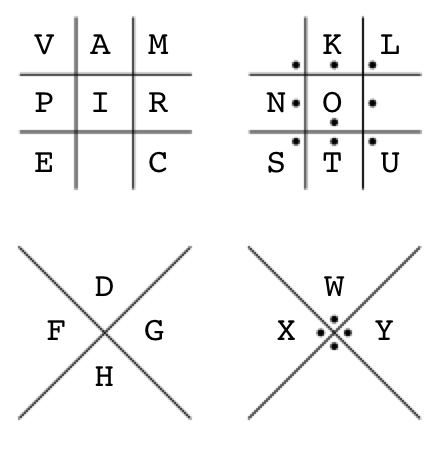
And for completeness, here’s the Pigpen code with the unused characters (B, J, Q, Z) in red:
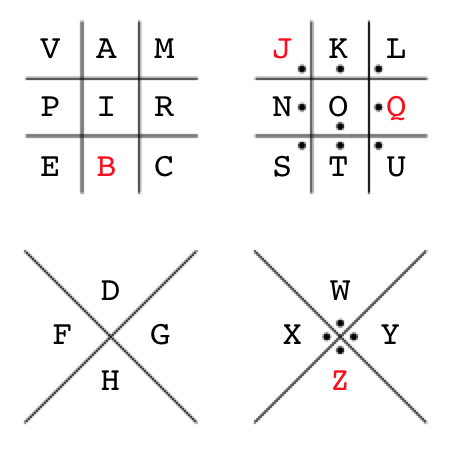
Summary
That was a lot of fun. And very frustrating. But mainly fun.
So how did this work? To be honest, I was hoping that the initial Pigpen attempt, the Pigpen Brute-force Key Rotation, or frequency analysis would have revealed more. I only started making real progress when I took the more manual approach of attempting different signatures.
That being said, the initial Pigpen rotation accidentally helped me solve a bunch of words in the ciphertexts (I WILL, NEXT ISSUE, IS ALWAYS) – why was that? Comparing my first Pigpen rotation attempt (below, left) with the final solved Pigpen, something interesting becomes visible; 7 mappings are the same (highlighted in green). Words in the ciphertext that contained K, L, W, X, & Y were already solved, which is why words like “WILL”, “NEXT”, and “ALWAYS” were mostly already solved (and easily visible in the script output).
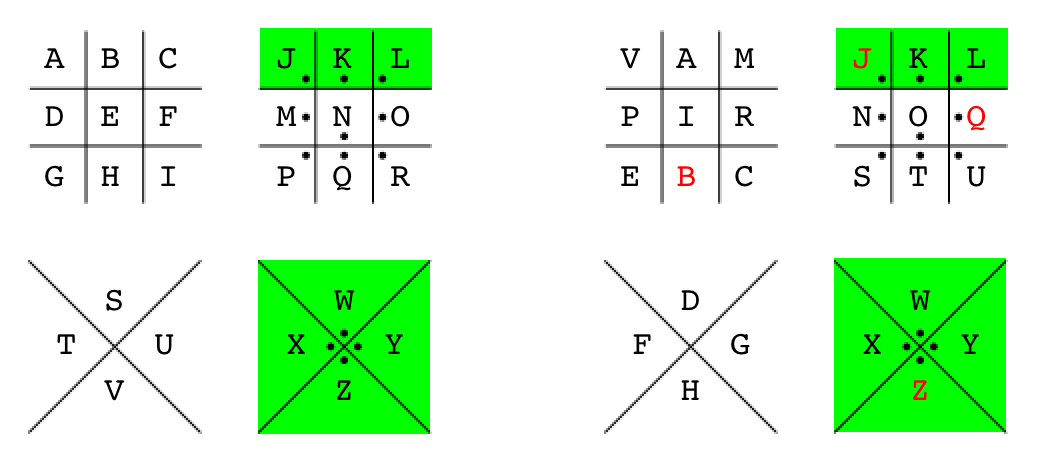
Initial Pigpen attempt (left), Adventure Time Pigpen keys (right), keys highlighted in green are the same for both sets of keys
What about the frequency analysis attempt? Now we have the solution, I’m interested in going back to see just how close the frequency analysis attempt was.
With the output from the frequency analysis script, there were a number of matching counts, e.g. E & G both with 12, M & B with 7:
Ciphertext => English (count) E => E (12) G => T (12) N => A (9) P => O (8) M => I (7) B => N (7) [...]
In the unsorted script output, there were 2 matches (C => M, K => K), or (100/26)*2= 7.9% correctly matched.
What if we were to rearrange only the matching counts to match the optimal order, i.e. swap E for G, and M for B:
Ciphertext => English (count) G => E (12) E => T (12) N => A (9) P => O (8) B => I (7) M => N (7) [...]
Now we have 4 matches (G => E, M => N, C => M, K => K), or (100/26)*4 = 15.4% correctly matched.
Here’s both the undetermined and optimal frequency analysis results next to one of the actual decrypted ciphers (even the optimal order is pretty tough to make anything meaningful out of):
Freq. analysis (undetermined order): EROIEFTRAUNYTNBSETIGLADKIAHEONCHNLOGAHIRASNWHERULAD-MNSFTCEIT Freq. analysis (optimal order): R’ONTFERAUIYEIBSTENGLADKNAHTOICHILOGAHNRASIWHTRULAD-MISFECTNE Actual: ITSNICETOHAVEAFRIENDYOUKNOWISALWAYSDOWNTORAPWITHYOU-MARCELINE
But the optimal frequency analysis result which correctly mapped 4 out of the available 26 characters still seems surprisingly good, particularly for such a short ciphertext. What is the probability that a random shuffle of the keys would perform at least as well as the optimum frequency analysis attempt? Luckily people much smarter than me have solved a similar problem (here):
From the brute force investigation, we know there are 26! possible permutations of the Pigpen key. The number of derangements (permutations where no key ends up in the correct position) is:
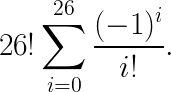
The number of permutations where exactly 4 keys are mapped to the correct position is the product of the number of derangements of 26−4 keys and the number of ways of choosing 4 keys among 26:
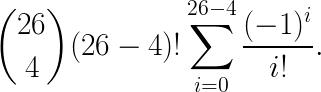
Finally, the probability of such a permutation is:
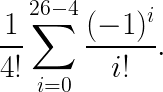
Which gives us (courtesy of Wolfram Alpha’s TeX solver):
6563440628747948887/428190753439088640000 ≈ 0.0153283
or ~1.5% probability that a random shuffle would have performed at least as well as the optimum frequency analysis attempt.
Full article available:

{kind=link}
Leave a comment